
客服工单系统上线智能分类后连续告警,AI把“物流延迟咨询”标记成“退款投诉”,把“账号绑定失败”归类成“密码重置”,后台日志显示模型全是凭空捏造的业务状态码。我们第一版就是这么写的,上线当天晚上11点,告警群炸了。
这不是个例,是Spring AI接入企业业务最常见的Function Calling幻觉问题,也是从Demo到落地必须跨过的第一道坎。
Spring AI的核心价值不是帮你调通大模型接口,而是把AI能力封装成可管控、可兼容、可事务化的企业级组件,屏蔽底层模型差异的同时,解决业务落地的核心痛点。我见过几个团队,demo跑得飞起,一上线这四个问题全炸:幻觉、流式响应事务、多模型切换、敏感数据管控。
Function Calling的幻觉问题,我们线上踩了三个月才填平。
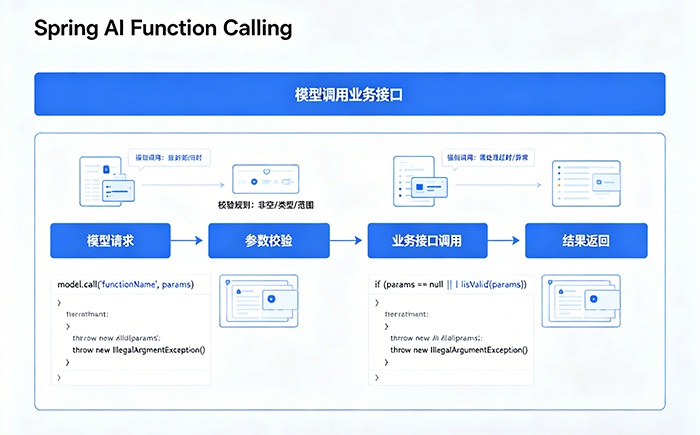
企业业务里,AI不能自由发挥,必须调用我们提供的业务接口获取真实数据,比如查询订单状态、校验用户权限、获取商品库存。模型一旦脱离真实接口自己编造结果,就是典型的幻觉,轻则业务报错,重则资损。
Spring AI的Function Calling本质是模型声明需要调用的函数→框架解析函数参数→执行真实业务方法→把结果回传给模型生成回答。这个链路里,90%的幻觉出在两个环节:模型伪造函数入参、模型跳过函数直接编造答案。
// 别这么写,我因为这个被线上告警吵醒过三次
@Bean
public Function<OrderRequest, OrderInfo> queryOrderFunction(OrderService orderService) {
return request -> orderService.getOrderInfo(request.getOrderId());
}
这个代码跑起来,模型会经常伪造一个不存在的orderId,甚至直接告诉你“订单已退款”,根本不调用你的queryOrderFunction。原因很简单,Spring AI默认是建议调用,不是强制调用。模型觉得自己能猜,就会跳过函数。但企业业务里,订单、支付、物流这类数据,模型没有权限猜,必须调用真实接口。
根治幻觉的核心,是给模型加双层锁:第一层强制指定必须调用的函数,第二层做入参强校验,拒绝非法参数。
Spring AI 1.0.0+提供了FunctionCallOptions,这是解决问题的关键。我们可以在构建ChatRequest时,强制锁定函数,不允许模型自主选择,同时自定义函数调用处理器,拦截伪造的入参。
// 正确写法:强制函数调用 + 参数合法性校验
ChatResponse response = chatClient.prompt()
.user(prompt)
.functions("queryOrderFunction")
.options(FunctionCallOptions.builder()
.mode(FunctionCallMode.FORCE) // 强制调用,不让模型自己猜
.build())
.call()
.chatResponse();
// 自定义函数调用后置处理器,拦截伪造参数
@Component
public class OrderFunctionProcessor implements FunctionCallbackProcessor {
@Override
public <T, R> Function<T, R> process(String functionName, Function<T, R> function) {
if ("queryOrderFunction".equals(functionName)) {
return request -> {
OrderRequest orderRequest = (OrderRequest) request;
// 订单号必须18位数字,否则直接抛异常。别信模型的格式,它会给你加空格
if (!Pattern.matches("\\d{18}", orderRequest.getOrderId())) {
throw new IllegalArgumentException("订单号格式非法,禁止调用业务接口");
}
return function.apply(request);
};
}
return function;
}
}
这两段代码解决了核心问题:强制调用让模型没有编造的机会,参数校验把伪造的请求拦在业务接口之外。你可能觉得加个校验就行,但真实落地中,模型会用各种方式绕过简单判断,比如把订单号加空格、用中文数字代替阿拉伯数字。只有把业务规则硬编码到处理器里,才能彻底杜绝幻觉。
更进一步,企业级场景需要函数调用结果缓存,避免重复调用接口增加耗时,同时做调用日志全量审计,这是监管要求。Spring AI的Advisor机制刚好能做这件事,不用侵入业务代码,就能实现敏感词过滤、日志记录、参数脱敏。
// 敏感词过滤 + 函数调用审计,不侵入业务代码
@Component
public class AISensitiveAdvisor implements SystemAdvisor {
private final SensitiveWordFilter filter = new SensitiveWordFilter();
private final AiLogService logService;
@Override
public List<ChatMessage> advise(List<ChatMessage> messages, AdvisorContext context) {
for (ChatMessage message : messages) {
String content = message.getContent();
String filteredContent = filter.filter(content);
message.setContent(filteredContent);
// 全量留存,合规必备
logService.saveAiLog(message.getRole(), filteredContent, context.getModelName());
}
return messages;
}
}
这个Advisor会自动拦截所有AI请求和响应,不管是单模型还是多模型,统一做敏感词处理和日志留存。很多人忽略这一步,上线后直接触发合规风险。
再说多模型适配,我们被OpenAI的账单吓到后才开始搞。
企业不可能只依赖OpenAI,内网需要Ollama部署本地大模型做数据安全,外网用OpenAI保证效果。Spring AI能无缝切换,核心就是AbstractChatClient这个抽象类。
翻源码会发现,不管是OpenAI、Ollama还是通义千问,Spring AI的所有ChatClient都继承自AbstractChatClient。OpenAI的实现里多了一个tools字段的组装逻辑,而Ollama直接用format: json强制结构化输出。但这个抽象类做了三件核心事:统一请求封装、统一函数调用解析、统一响应解析。我们基于它做一层二次抽象,就能实现业务代码零改动切换模型。
// 业务代码不感知底层模型,切换只需要改路由规则
public abstract class EnterpriseChatClient extends AbstractChatClient {
protected final ChatModel openAiChatModel;
protected final ChatModel ollamaChatModel;
protected EnterpriseChatClient(ChatModel openAiChatModel, ChatModel ollamaChatModel) {
super(openAiChatModel);
this.openAiChatModel = openAiChatModel;
this.ollamaChatModel = ollamaChatModel;
}
// 动态路由:敏感数据走本地Ollama,外网通用请求走OpenAI
protected ChatModel routeModel(boolean isInternalData) {
return isInternalData ? ollamaChatModel : openAiChatModel;
}
@Override
protected ChatResponse doCall(ChatRequest chatRequest) {
// 统一加一层企业级prompt,避免模型瞎编
ChatRequest enterpriseRequest = ChatRequest.builder()
.from(chatRequest)
.systemMessage("你是企业专属助手,仅使用提供的业务数据回答,禁止编造信息")
.build();
return super.doCall(enterpriseRequest);
}
}
AbstractChatClient的call()方法是模板方法模式,子类只需要重写doCall(),就能实现统一的业务增强。这个抽象层把模型切换、统一prompt、参数校验全部封装,业务Service直接调用,不用关心底层是哪个模型。
最后说流式输出的事务一致性,这个坑我们填了两天。
AI客服、AI报表生成这类场景,流式响应需要实时把数据推给前端,同时业务需要生成报表记录、扣减资源。传统的@Transactional事务会出现问题:流式数据已经推给用户了,事务回滚了,前后数据不一致。
Spring AI的流式响应是基于Flux实现的。核心思路是把流式输出和事务解耦:事务只负责业务数据落地,流式输出监听事务状态,成功后再推送最终结果,失败则推送错误信息。
// 别直接在流式方法上加@Transactional,会炸
public Flux<String> streamOrderInfo(Long orderId) {
TransactionTemplate transaction = new TransactionTemplate(transactionManager);
return transaction.execute(status -> {
try {
OrderInfo order = orderService.getOrderInfo(orderId);
orderWorkOrderService.createWorkOrder(order); // 事务操作
// 事务成功后再流式输出
return chatClient.prompt()
.user("解析订单信息:" + JSON.toJSONString(order))
.stream()
.content();
} catch (Exception e) {
status.setRollbackOnly();
return Flux.just("订单查询失败,请稍后重试");
}
});
}
关键点:事务提交成功后,AI才会开始流式输出;事务回滚则直接返回错误信息。前端不会收到“一半的数据”。很多开发直接在流式方法上加@Transactional,结果就是响应推了一半事务回滚,线上bug直接爆炸。
Spring AI落地企业业务,从来不是调通接口就完事。函数调用强制约束解决幻觉,AbstractChatClient抽象层解决多模型兼容,Advisor解决合规管控,事务解耦解决流式一致性。
企业里的AI应用,不需要模型有多聪明,需要的是稳定、可控、合规、不编造、不宕机。把AI当成一个标准化的业务组件,而不是一个黑盒玩具,才是Spring AI真正的落地方式。
业务数据不进黑盒,函数调用强约束,多模型抽象化,流式事务解耦,AI落地无风险。