
在Java并发编程领域,线程是处理多任务的基础载体,但很多开发者在初期都会踩一个坑:频繁创建、销毁线程不仅会带来巨大的系统开销,还可能因为无限制创建线程导致资源耗尽、服务崩溃。而线程池,作为并发编程的“效率神器”,通过统一管理、复用线程的核心机制,完美解决了这一痛点——它既能降低资源消耗,又能提升响应速度,还能实现对线程的精细化控制与监控。
今天,这篇文章就带你从“线程基础”入门,一步步吃透ThreadPoolExecutor的核心原理、源码细节,再到SpringBoot实战异步批量处理百万级数据,全篇干货无冗余,无论是新手入门还是老手复盘,都能有所收获。
一、基础铺垫:Java中线程创建的4种方式
在聊线程池之前,我们先回顾下Java中创建线程的几种核心方式——这是理解线程池“复用线程”思想的基础,毕竟只有知道线程怎么来的,才能明白“复用”到底优化了什么。
1.1 继承 Thread 类创建线程
这种方式是最直观的线程创建方式,通过继承Thread类,重写run()方法定义线程执行逻辑,再通过start()方法启动线程。需要注意的是,start()方法才是真正启动线程,而直接调用run()方法只是普通的方法调用,不会开启新线程。
示例代码:
public class MyThread extends Thread {
@Override
public void run() {
String name = Thread.currentThread().getName();
if ("xc1".equals(name)) {
for (int i = 0; i < 100; i++) {
System.out.println(name + ":" + i);
}
} else if ("xc2".equals(name)) {
for (int i = 0; i < 10; i++) {
System.out.println("好好学习java" + i);
}
}
}
}
// 测试类
public class Test {
public static void main(String[] args) {
MyThread t1 = new MyThread();
t1.setName("xc1");
t1.start();
MyThread t2 = new MyThread();
t2.setName("xc2");
t2.start();
}
}
1.2 实现 Runnable 接口创建线程
由于Java是单继承机制,继承Thread类会限制类的扩展性,因此实际开发中更常用“实现Runnable接口”的方式创建线程。这种方式将线程执行逻辑与线程对象分离,灵活性更高。
核心步骤:定义Runnable实现类→重写run()方法→将实现类实例作为参数构造Thread对象→启动线程。
示例代码:
public class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
// 测试类
public class Test1 {
public static void main(String[] args) {
Runnable target = new MyRunnable();
Thread t1 = new Thread(target, "线程1");
Thread t2 = new Thread(target, "线程2");
t1.start();
t2.start();
}
}
1.3 实现 Callable 接口创建线程
上面两种方式的run()方法都没有返回值,也无法抛出受检异常。如果我们需要线程执行完成后返回结果(比如计算一个复杂数值),就需要使用Callable接口,搭配FutureTask来获取返回值。
核心优势:带返回值、可抛出异常,适合需要获取线程执行结果的场景。
示例代码:
public class MyCallable implements Callable {
@Override
public Integer call() {
return 11 + 22; // 线程执行逻辑,返回计算结果
}
}
// 测试类
public class Test2 {
public static void main(String[] args) throws Exception {
FutureTask task = new FutureTask<>(new MyCallable());
new Thread(task, "线程一").start();
Integer result = task.get(); // 获取线程执行结果,会阻塞直到结果返回
System.out.println("线程执行结果:" + result);
}
}
1.4 使用线程池创建线程
上面三种方式,每次创建线程都是“用完即毁”,频繁创建销毁会浪费大量系统资源(比如CPU调度、内存分配)。而线程池的核心思想就是“复用线程”——提前创建一批线程,任务完成后不销毁,而是放回线程池供后续任务复用,这也是企业级开发中最推荐的线程使用方式。
接下来,我们就深入拆解线程池的核心原理,吃透ThreadPoolExecutor的底层逻辑。
二、核心概念:线程池到底是什么?为什么要用?
在深入源码之前,我们先理清几个关键概念,避免后续理解源码时混淆——很多开发者觉得线程池难,其实是没搞懂基础概念。
2.1 先分清:并发和并行的区别
聊线程池,绕不开“并发”和“并行”,这两个概念经常被混淆,用一句话讲明白:
• 并发:单个或多个CPU核心,线程快速切换执行,宏观上看起来“同时执行”,微观上是交替执行(比如一个CPU同时处理多个APP的请求,本质是快速切换)。
• 并行:多个CPU核心同时执行不同线程,是真正意义上的“同时执行”(比如电脑同时开着视频、音乐,两个任务在不同CPU核心上运行)。
线程池的作用,就是在“并发”场景下,高效管理线程,避免资源浪费。
2.2 什么是线程池?
简单来说,线程池就是一个“线程容器”,它会提前维护一定数量的存活线程,当有任务提交时,直接从容器中取出线程执行任务;任务完成后,线程不会被销毁,而是放回容器,等待下一个任务。
核心价值:统一管理线程,实现线程复用,解决“频繁创建销毁线程”的痛点。
2.3 为什么必须用线程池?(企业级开发痛点)
很多新手会问:“我直接创建线程不行吗?为什么非要用线程池?” 答案很简单——为了稳定、高效,具体有4个核心优势:
1. 降低资源消耗:复用线程,避免频繁创建、销毁线程带来的CPU和内存开销(线程的创建和销毁属于重量级操作)。
2. 提高响应速度:任务到达时,无需等待线程创建,直接使用线程池中的空闲线程执行,减少任务等待时间。
3. 提升线程可管理性:通过线程池可以统一分配、调优、监控线程,防止无限制创建线程导致的资源耗尽(比如一个接口并发量高时,创建上千个线程,直接把JVM内存撑爆)。
4. 增强系统稳定性:通过控制最大并发数,限制线程数量,避免资源耗尽,保证服务稳定运行。
三、源码解读:ThreadPoolExecutor 核心原理
ThreadPoolExecutor是Java线程池的核心实现类,所有线程池的底层逻辑都围绕它展开(比如Executors工具类创建的线程池,本质也是基于ThreadPoolExecutor)。想要用好线程池,必须吃透它的核心参数、执行流程和源码逻辑。
3.1 线程池的7个核心参数
ThreadPoolExecutor的构造方法是核心,它的7个参数决定了线程池的行为,先看源码中的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
每个参数的作用,用通俗的语言解释清楚,避免生硬的概念:
• corePoolSize(核心线程数):线程池中的“常驻线程”数量,即使这些线程空闲,也不会被回收(默认情况下),随时等待任务。
• maximumPoolSize(最大线程数):线程池能容纳的最大线程数,包括核心线程和非核心线程(非核心线程是临时创建的,任务完成后会被回收)。
• keepAliveTime(空闲线程存活时间):非核心线程空闲后的存活时间,超过这个时间,非核心线程会被回收;如果设置了allowCoreThreadTimeOut(true),核心线程也会被回收。
• unit(时间单位):keepAliveTime的时间单位,比如TimeUnit.SECONDS(秒)、TimeUnit.MILLISECONDS(毫秒)。
• workQueue(阻塞队列):用于存储等待执行的任务,当核心线程都在忙,且任务数量超过核心线程数时,任务会进入这个队列等待。
• threadFactory(线程工厂):用于创建线程的工厂,可以自定义线程的名称、优先级等(比如给线程命名,方便排查日志)。
• handler(拒绝策略):当线程池已满(线程数达到最大,队列也满了),再提交任务时的处理方式,有4种默认策略。
3.2 线程池任务执行流程
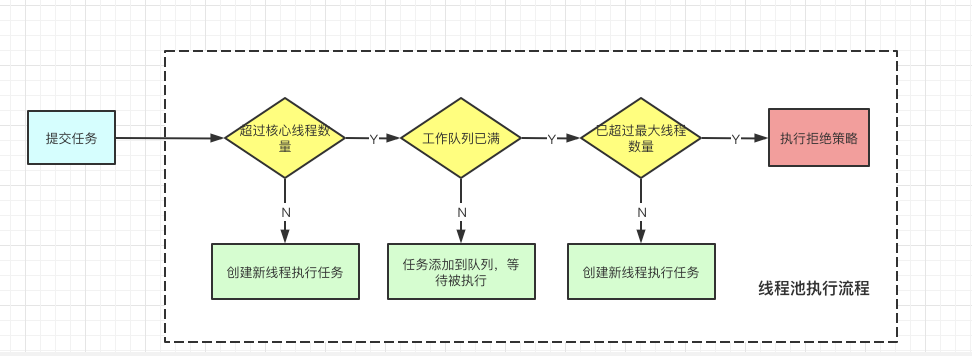
理解了核心参数,再看任务提交后,线程池是如何处理的——这是线程池的核心逻辑,用4步就能讲明白,结合参数更容易理解:
1. 当提交一个任务时,首先判断当前线程数是否小于corePoolSize(核心线程数):如果是,直接创建核心线程执行任务。
2. 如果当前线程数≥corePoolSize,且阻塞队列(workQueue)未满:将任务放入队列,等待核心线程空闲后执行。
3. 如果队列已满,且当前线程数
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException(); // 任务不能为null
int c = ctl.get(); // 获取当前线程池状态和线程数
// 1. 线程数 < 核心线程数,创建核心线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get(); // 重新获取状态(防止并发修改)
}
// 2. 线程池运行中,且任务能加入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 重新检查:如果线程池已停止,移除任务并执行拒绝策略
if (!isRunning(recheck) && remove(command))
reject(command);
// 如线程数为0,创建非核心线程(兜底,避免队列有任务但无线程执行)
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3. 队列满了,尝试创建非核心线程;创建失败则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
源码逻辑和我们之前讲的“任务执行流程”完全一致,理解了这个方法,就吃透了线程池的核心运行机制。
四、实战落地:SpringBoot 线程池异步处理百万级数据
理论讲再多,不如实战练一次。实际开发中,最常见的场景就是“批量处理数据”(比如批量插入百万条用户数据),如果用单线程处理,耗时会非常长;而用SpringBoot整合线程池,实现异步批量处理,能大幅提升效率。
下面我们从零搭建一个SpringBoot项目,实现百万级数据异步批量插入,所有代码可直接复制使用。
4.1 项目依赖(pom.xml)
引入SpringBoot Web、MyBatis-Plus、MySQL驱动、Druid连接池等核心依赖
org.springframework.bootspring-boot-starter-web com.baomidoumybatis-plus-spring-boot3-starter3.5.6 com.mysqlmysql-connector-j com.alibabadruid-spring-boot-starter1.2.8 org.projectlomboklomboktrue
4.2 数据库表设计(MySQL)
创建一个简单的用户表,用于存储批量插入的数据:
CREATE DATABASE IF NOT EXISTS test01 DEFAULT CHARACTER SET utf8; USE test01; CREATE TABLE sys_user ( user_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '编号', user_name VARCHAR(20) DEFAULT NULL COMMENT '用户名', user_age INT(11) DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
4.3 配置文件(application.yml)
配置数据库连接和MyBatis-Plus相关参数:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test01?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root # 替换成你的MySQL用户名
password: root # 替换成你的MySQL密码
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 下划线转驼峰
type-aliases-package: cn.hxzy.domain # 实体类包路径,根据自己的项目修改
4.4 实体类(User.java)
使用Lombok简化实体类编写,对应sys_user表:
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("sys_user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type = IdType.AUTO) // 自增主键
private Long userId;
private String userName;
private Integer userAge;
}
4.5 Mapper接口(UserMapper.java)
继承MyBatis-Plus的BaseMapper,无需编写SQL,直接调用内置方法:
@Repository
public interface UserMapper extends BaseMapper {
}
4.6 Service层(UserService.java)
继承MyBatis-Plus的IService和ServiceImpl,复用内置的批量保存方法:
public interface UserService extends IService {
}
@Service
public class UserServiceImpl extends ServiceImpl implements UserService {
}
4.7 线程池配置(ThreadPoolConfig.java)
核心配置类,开启异步注解(@EnableAsync),自定义线程池参数——这里的参数配置是关键,后续会讲调优技巧:
@Configuration
@EnableAsync // 开启Spring异步支持
public class ThreadPoolConfig {
@Bean("asyncTaskExecutor") // 自定义线程池Bean名称,后续异步方法指定使用
public Executor asyncTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 获取CPU核心数,根据CPU核心数设置线程数(推荐配置)
int cpu = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(cpu * 2); // 核心线程数:CPU核心数*2(IO密集型任务)
executor.setMaxPoolSize(cpu * 4); // 最大线程数:CPU核心数*4
executor.setQueueCapacity(500); // 阻塞队列容量,避免队列过大导致内存溢出
executor.setKeepAliveSeconds(60); // 空闲线程存活时间:60秒
executor.setThreadNamePrefix("async-"); // 线程名称前缀,方便日志排查
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 拒绝策略
executor.setAllowCoreThreadTimeOut(true); // 允许核心线程超时回收
executor.initialize(); // 初始化线程池
return executor;
}
}
4.8 异步任务Service(AsyncBatchService.java)
定义异步批量插入方法,使用@Async注解指定使用我们自定义的线程池:
public interface AsyncBatchService {
// 批量插入用户数据,latch用于等待所有子线程完成
void batchInsert(List list, CountDownLatch latch);
}
@Service
public class AsyncBatchServiceImpl implements AsyncBatchService {
@Autowired
private UserService userService;
@Override
@Async("asyncTaskExecutor") // 指定使用自定义的线程池
@Transactional(rollbackFor = Exception.class) // 事务控制,异常回滚
public void batchInsert(List list, CountDownLatch latch) {
try {
// 批量保存,每次插入100条(MyBatis-Plus内置方法)
userService.saveBatch(list, 100);
} catch (Exception e) {
e.printStackTrace(); // 实际开发中建议用日志框架记录异常
} finally {
latch.countDown(); // 子线程执行完成,计数器减1
}
}
}
4.9 集合拆分工具类(ListUtils.java)
将百万条数据拆分成多个小集合,避免单次插入数据过多导致数据库压力过大:
public class ListUtils {
/**
* 拆分集合
* @param list 待拆分集合
* @param size 每个子集合的大小
* @param 集合泛型
* @return 拆分后的子集合列表
*/
public static List> split(List list, int size) {
if (CollectionUtils.isEmpty(list) || size <= 0) {
return new ArrayList<>();
}
List> result = new ArrayList<>();
int total = list.size();
// 计算需要拆分的子集合数量
int count = (total + size - 1) / size;
for (int i = 0; i < count; i++) {
int start = i * size;
int end = Math.min((i + 1) * size, total);
result.add(new ArrayList<>(list.subList(start, end)));
}
return result;
}
}
4.10 Controller层(UserController.java)
编写接口,生成百万条测试数据,拆分后异步批量插入,并用CountDownLatch等待所有子线程完成:
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private AsyncBatchService asyncBatchService;
@PostMapping("/batchAdd")
public String batchAdd() {
long start = System.currentTimeMillis(); // 记录开始时间
List list = new ArrayList<>();
Random random = new Random();
// 生成100万条测试数据
for (int i = 0; i < 1000000; i++) {
User user = new User();
user.setUserName("用户:" + i);
user.setUserAge(random.nextInt(60)); // 随机年龄(0-59)
list.add(user);
}
// 将100万条数据拆分成每个500条的子集合
List> partitions = ListUtils.split(list, 500);
// CountDownLatch:计数器,用于等待所有子线程完成
CountDownLatch latch = new CountDownLatch(partitions.size());
// 遍历子集合,提交异步任务
for (List part : partitions) {
asyncBatchService.batchInsert(part, latch);
}
try {
// 等待所有子线程完成,超时时间10分钟
boolean ok = latch.await(10, TimeUnit.MINUTES);
if (!ok) {
log.warn("批量插入任务超时");
}
} catch (InterruptedException e) {
log.error("等待异常", e);
Thread.currentThread().interrupt();
}
long end = System.currentTimeMillis(); // 记录结束时间
log.info("百万级数据批量插入完成,总耗时:{}s", (end - start) / 1000);
return "批量插入完成,总耗时:" + (end - start) / 1000 + "s";
}
}
测试说明:启动项目后,调用POST接口http://localhost:8080/user/batchAdd,即可执行百万级数据异步批量插入,控制台会输出总耗时(一般几十秒,比单线程快10倍以上)。
五、同步工具:CountDownLatch 解析
上面的实战案例中,我们用到了CountDownLatch,很多新手对这个工具类不熟悉,这里单独拆解——它是JUC中的核心同步工具,专门用于“主线程等待一组子线程全部完成后再继续执行”。
5.1 CountDownLatch 的核心作用
通俗来说,CountDownLatch就像一个“计数器”:主线程创建一个计数器,然后启动多个子线程;每个子线程执行完成后,计数器减1;主线程阻塞等待,直到计数器变为0,才继续执行后续逻辑。
比如上面的批量插入场景:主线程拆分数据后,启动多个子线程异步插入;主线程需要等待所有子线程都插入完成,才能计算总耗时,这时候就需要用CountDownLatch。
5.2 核心方法(3个,必记)
• countDown():计数器减1,由子线程执行(一般放在finally中,确保即使子线程异常,计数器也会减1)。
• await():主线程阻塞等待,直到计数器变为0,才继续执行(无超时时间,可能永久阻塞)。
• await(time, unit):带超时时间的等待,超过指定时间后,无论计数器是否为0,主线程都会继续执行,避免永久阻塞(实际开发中优先使用这个方法)。
5.3 简单使用示例
用一个简单的案例,理解CountDownLatch的使用逻辑:
@Slf4j
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
int threadNum = 3; // 3个子线程
CountDownLatch latch = new CountDownLatch(threadNum); // 计数器初始值为3
for (int i = 1; i <= threadNum; i++) {
int no = i;
new Thread(() -> {
try {
log.info("线程{}执行中", no);
TimeUnit.SECONDS.sleep(2); // 模拟线程执行耗时
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
latch.countDown(); // 子线程执行完成,计数器减1
log.info("线程{}执行完毕,计数器剩余:{}", no, latch.getCount());
}
}).start();
}
log.info("主线程等待所有子线程完成...");
latch.await(30, TimeUnit.SECONDS); // 等待30秒,超时则继续
log.info("所有线程执行完毕,主线程继续执行");
}
}
运行结果:3个子线程同时执行,2秒后全部完成,计数器变为0,主线程继续执行,完美实现“主线程等待子线程”的需求。
结尾总结:线程池使用最佳实践
线程池是Java高并发编程的基石,用好ThreadPoolExecutor,能让你的系统吞吐量翻倍、稳定性提升一个档次。结合本文的知识点和实战案例,总结几个实际开发中的最佳实践,避坑必备:
1. 线程数配置:CPU密集型任务(比如计算),核心线程数设置为CPU核心数+1;IO密集型任务(比如数据库操作、接口调用),核心线程数设置为CPU核心数*2(因为IO操作会阻塞线程,需要更多线程提高效率)。
2. 队列选择:优先使用有界队列(比如ArrayBlockingQueue),避免使用无界队列(比如LinkedBlockingQueue),防止任务过多导致队列无限膨胀,撑爆JVM内存。
3. 拒绝策略选择:根据业务场景选择,核心业务(比如支付、下单)用AbortPolicy,确保任务不丢失;非核心业务(比如日志)用DiscardPolicy,避免影响核心流程。
4. 异步任务控制:异步任务要做好事务控制(比如@Transactional)、异常处理(避免子线程异常导致任务丢失)和超时控制(比如CountDownLatch的await带超时)。
5. 避免使用Executors:Executors工具类创建的线程池(比如newFixedThreadPool、newCachedThreadPool),存在队列无界、线程数无限制等问题,实际开发中建议自定义ThreadPoolExecutor。
最后,线程池的核心是“复用”和“管控”,只要理解了它的核心参数、执行流程,再结合实际业务场景调优,就能轻松应对高并发场景。希望这篇文章能帮你吃透ThreadPoolExecutor,从基础到实战,真正掌握并发编程的核心技巧。